Bienvenido a la web del CICA
Miércoles, 24 de Abril del 2024
Noticias 
-
 Visita IES San Jerónimo
Visita IES San Jerónimo22 de diciembre del 2023
Agradecemos la visita de los alumnos del IES San Jerónimo al CICA para conocer nuestras instalaciones, así como los servicios que prestamos a la comunidad
[...]






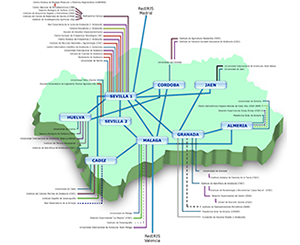
El Centro Informático Científico de Andalucía (CICA) es un centro concebido para prestar servicios a la comunidad científica andaluza, que le ayuden en el desarrollo de su labor investigadora.
Creado en el año 1989 por el Decreto 43/89 de 7 de marzo, actualmente depende de la Agencia Digital de Andalucía, perteneciente a la Consejería de la Presidencia, Interior, Diálogo Social y Simplificación Administrativa de la Junta de Andalucía.
Red RICA
eCiencia

Repositorio

Visitas

Contacto
